Word的查找功能,也支持正则表达式(MS-HELP),你知道吗?

概述
正则表达式(Regular Expression)是一种匹配模式,描述的是一串文本的特征。正如自然语言中“高大”、“坚固”等词语抽象出来描述事物特征一样,正则表达式就是字符的高度抽象,用来描述字符串的特征。
正则表达式(以下简称正则,Regex)通常不独立存在,各种编程语言和工具作为宿主语言提供对正则的支持,并根据自身语言的特点,进行一定的剪裁或扩展。
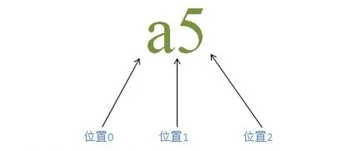
对于字符串“a5”,是由两个字符“a”、“5”以及三个位置组成的,这一点对于正则表达式的匹配原理理解很重要。
基础
正则表达式由两种字符构成。一种是在正则表达式中具体特殊意义的“元字符”,另一种是普通的“文本字符”。
元字符可以是一个字符,如“^”,也可以是一个字符序列,如“\w”。
字符组
字符组可以匹配[ ]中包含的任意一个字符。虽然可以是任意一个,但只能是一个。字符组支持由连字符“-”来表示一个范围。当“-”前后构成范围时,要求前面字符的码位小于后面字符的码位。
[^…] 排除型字符组。排除型字符组表示任意一个未列出的字符,同样只能是一个。排除型字符组同样支持由连字符“-”来表示一个范围。
| 表达式 | 说明 |
| [abc] | 表示“a”或“b”或“c” |
| [0-9] | 表示0~9中任意一个数字,等价于[0123456789] |
| [\u4e00-\u9fa5] | 表示任意一个汉字 |
| [^a1<] | 表示除“a”、“1”、“<”外的其它任意一个字符 |
| [^a-z] | 表示除小写字母外的任意一个字符 |
举例:
[0-9][0-9] 在匹配“Windows 2003”时,匹配成功,匹配的结果为“20”。
[^inW] 在匹配“Windows 2003”时,匹配成功,匹配的结果为“d”。
预定义字符集
对于一些常用的字符范围,如数字等,由于非常常用,即使使用[0-9]这样的字符组仍显得麻烦,所以定义了一些元字符,来表示常见的字符范围。
小写是匹配,大写是不匹配。w字母数字下划线,d数字,s空白字符。
| 表达式 | 说明 |
| \d | 任意一个数字,相当于[0-9],即0~9 中的任意一个 |
| \w | 任意一个字母或数字或下划线,相当于[a-zA-Z0-9_] |
| \s | 任意空白字符,相当于[ \r\n\f\t\v] |
| \D | 任意一个非数字字符,\d取反,相当于[^0-9] |
| \W | \w取反,相当于[^a-zA-Z0-9_] |
| \S | 任意非空白字符,\s取反,相当于[^ \r\n\f\t\v] |
| . | 匹配除了换行符 \n 以外的任意一个字符; 如果要匹配包括“\n”在内的所有字符,一般用[\s\S]。 |
举例:
\w\s\d 在匹配“Windows 2003”时,匹配成功,匹配的结果为“s 2”。
定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
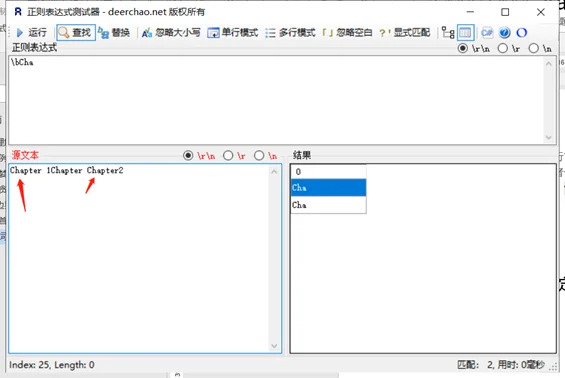
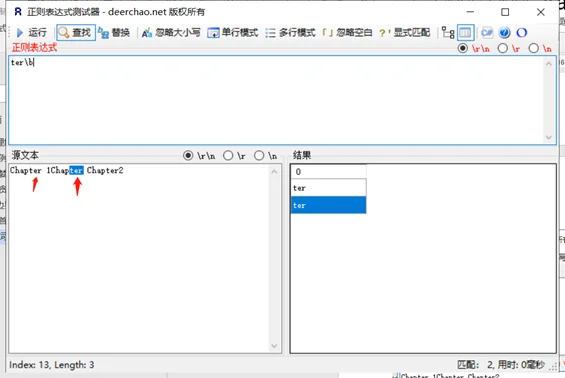
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
| 字符 | 描述 |
| ^ | 从行首位置开始匹配。 |
| $ | 从行未位置检查匹配。 |
| \b \B | 单词界定\b与非单词界定\B 注意:是否匹配一个词边界,各软件定义不一样的。 |
举例:
^a 在匹配“cba”时,匹配失败,因为表达式要求开始位置后面是字符“a”。
^The 匹配行开头为the/THE(大小写区分,取决于当前软件是否支持),但athe不是。
end$ 匹配行结尾为end/END(大小写区分,取决于当前软件是否支持),但enda不是。
\d$ 在匹配“123”时,匹配成功,匹配结果为“3”,这个表达式要求匹配结尾处的数字,如果结尾处不是数字,如“123abc”,则是匹配失败的。
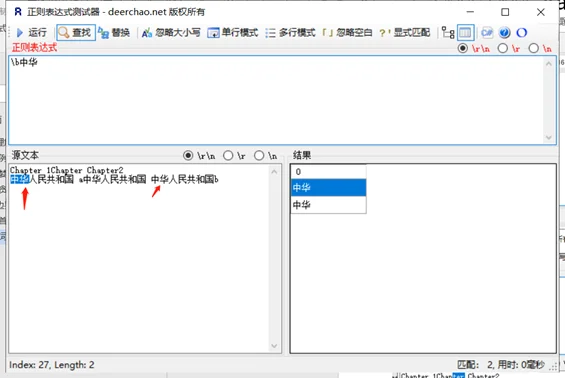
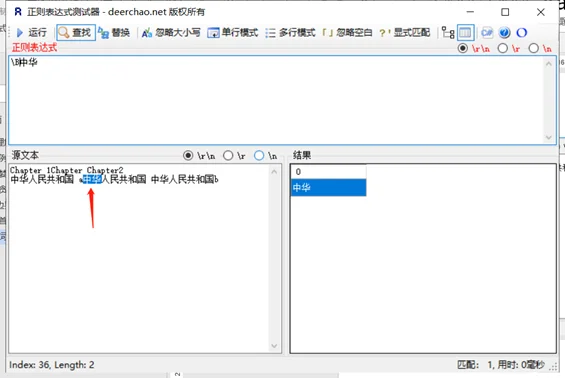
单词界定\b与非单词界定\B
示例内容:Chapter 1Chapter Chapter2
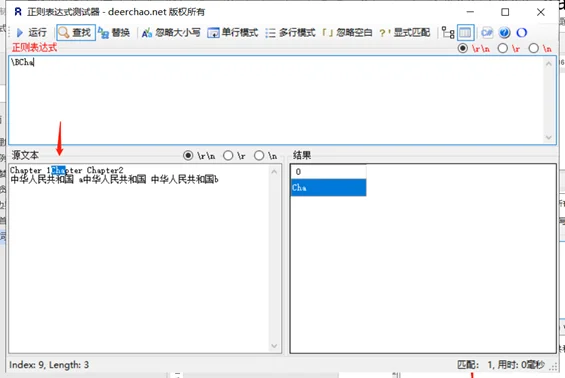
示例内容:中华人民共和国 a中华人民共和国 中华人民共和国b
非打印字符
| 字符 | 描述 |
| \cx | 匹配由x指明的控制字符。 例如\cM匹配一个Control-M或回车符,x的值必须为A-Z或a-z之一。 |
| \f | 匹配一个换页符。等价于\x0c和\cL。 |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d和\cM。 |
| \t | 匹配一个制表符。等价于\x09和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK。 |
\r\n使用时,要注意当前软件与OS的区别,有的软件正则式中,是不区分,有的是区分的;而OS中,Windows的同时有\r\n,Mac与Linux又不一样的。
转义字符
如果在正式表式中查找(正式表达工自身字符)时,前缀转义字符即可。
将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。
| 转义字符 | \ |
| 举例 | 匹配$字符:\$ 匹配*字符:\* 匹配+字符:\+ 匹配.字符:\. 匹配[字符:\[ 匹配?字符:\? 匹配/字符:\/ 匹配\字符:\\ 匹配{字符:\{ |
| 例外 | 在[]中不需要转义字符。 因为不会这样书写:^写成[^]、d-z写成[d-] |
/:在某些语言中表示正则表达式的开始或结束,而VBScript中使用“”做边界符。
子表达式
| 字符 | 说明 | 举例 |
|---|---|---|
| | | 多个子表达式之间取“或”的关系;如是字符串可书写任意长度。 | (t|T)(h|H) 等价为[tT][hH],也等价为(Th|tH|th|TH) 注意:不同软件对大小写定义不一样。 |
| ( ) | 要匹配的表达式,获取后可以反向引用(见捕获组)。()里可以放[]{},但[]{}里不能放() |
举例:
^aa|b$ 在匹配“cccb”时,是可以匹配成功的,匹配的结果是“b”,因为这个表达式表示匹配“^aa”或“b$”,而“b$”在匹配“cccb ”时是可以匹配成功的。
^(aa|b)$ 在区配“cccb”时,是匹配失败的,因为这个表达式表示在“开始”和“结束”位置之间只能是“aa”或“b”,而“cccb”显然是不满足的。
量词:匹配的次数
量词表示一个子表达式可以匹配的次数。量词可以用来修饰一个字符、字符组,或是用()括起来的子表达式。一些常用的量词被定义成独立的元字符。
| 字符 | 说明 | 举例 |
|---|---|---|
| ? | 匹配前面的子表达式0次或1次。 等价为{0,1} | ab? 匹配a或ab或abb。 |
| * | 匹配前面的子表达式0次或任意多次。 等价为{0,} | [^a]* 匹配b或ca,不是a或ab。 |
| + | 匹配前面的子表达式1次或任意多次。 等价为{1,} | \d\s+\d 两个数字中间至少有一个以上的空白字符。 |
| {m,n} | 前面子表达式的匹配长度,有以下三种形式: {m}:匹配前面的子表达式m次,所以{1}无意义。{m,n}:匹配前面的子表达式最少m次,最多n次。{m,}:匹配前面的子表达式至少m次。 | \d{3} 相当于\d\d\d (abc){2} 相当于abcabc \d{2,3} 匹配2-3位的数字。 [a-z]{8,} 至少8位以上的字母 ^[0-9]{1,20}$:仅1-20位的数字行。 |
举例:
^[a-zA-Z]{1}([a-zA-Z0-9]|[.@_]){4,19}$ 匹配以字母开头,可带数字小数点@下划线的长度5-20字符串的行。
模式修饰符
模式修饰符的作用是设定模式。也就是规定正则表达式应该如何解释和应用。不同的语言/软件都有自己的模式设置,所以了解即可。PHP中的主要模式如表所示:
