两个类型的组都是对匹配进行限制,区别在于一个可引用,另一个不能引用。
捕获组:可以引用
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或手动命名的组里,以供后面引用。普通捕获组(在不产生歧义的情况下,简称捕获组)是以数字进行编号的,编号规则是以“(”从左到右出现的顺序,从1开始进行编号。通常情况下,编号为0的组表示整个表达式匹配的内容。
| 表达式 | 说明 |
| (Expression) | 普通捕获组,将子表达式Expression匹配的内容保存到以数字编号的组里 |
| (?<name> Expression) | 命名捕获组,将子表达式Expression匹配的内容保存到以name命名的组里 |
命名捕获组可以通过捕获组名,而不是序号对捕获内容进行引用,提供了更便捷的引用方式,不用关注捕获组的序号,也不用担心表达式部分变更会导致引用错误的捕获组。
非捕获组:不能引用
一些表达式中,【不得不使用( ),但又不需要保存( )中子表达式匹配的内容】,这时可以用非捕获组来抵消使用( )带来的副作用。
| 表达式 | 说明 |
| (?:Expression) | 进行子表达式Expression的匹配,并将匹配内容保存到最终的整个表达式的区配结果中,但Expression匹配的内容不单独保存到一个组内。 |
另外,还有一种环视,也是只进行子表达式的匹配,匹配内容不计入最终的匹配结果,是零宽度的。环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视。
环视相当于对所在位置加了一个附加条件。
| 表达式 | 说明 |
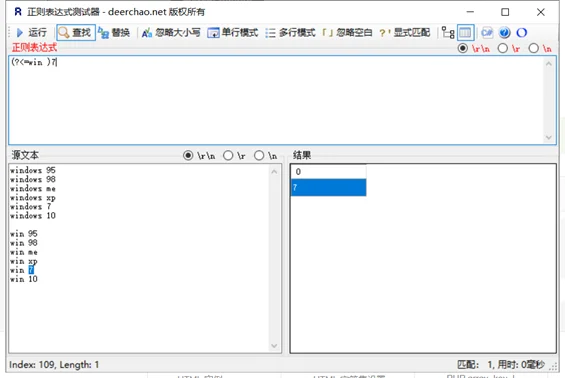
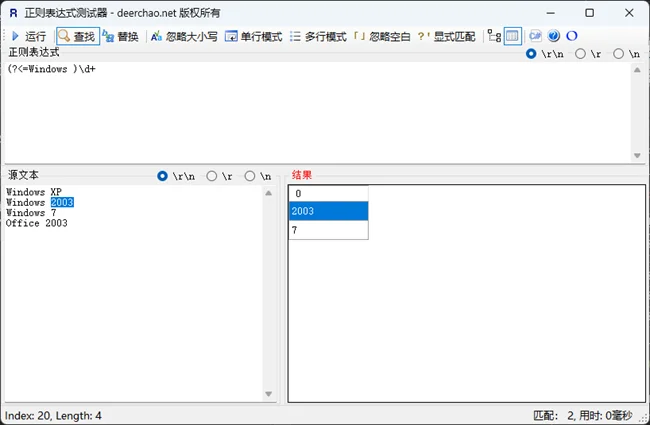
| (?<=Expression) | 逆序肯定环视,表示所在位置左侧能够匹配Expression |
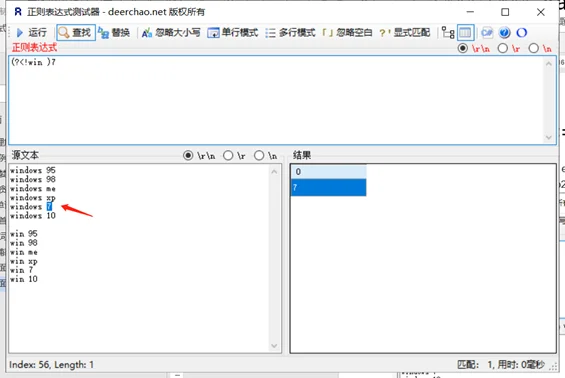
| (?<!Expression) | 逆序否定环视,表示所在位置左侧不能匹配Expression |
| (?=Expression) | 顺序肯定环视,表示所在位置右侧能够匹配Expression |
| (?!Expression) | 顺序否定环视,表示所在位置右侧不能匹配Expression |
举例:
“(?<=Windows )\d+”在匹配“Windows 2003”时,匹配成功,匹配结果为“2003”。我们知道“\d+”表示匹配一个以上的数字,而“(?<=Windows )”相当于一个附加条件,表示所在位置左侧必须为“Windows ”,它所匹配的内容并不计入匹配结果。同样的正则在匹配“Office 2003”时,匹配失败,因为这里任意一串数字子串的左侧都不是“Windows ”。
“(?!1)\d+”在匹配“123”时,匹配成功,匹配的结果为“23”。“\d+”匹配一个以上数字,但是附加条件“(?!1)”要求所在位置右侧不能是“1”,所以匹配成功的位置是“2”前面的位置。
反向引用:也可以用于查找中
捕获组匹配的内容,可以在正则表达式的外部程序中进行引用,也可以在表达式中进行引用,表达式中引用的方式就是反向引用。
反向引用通常用来查找重复的子串,或是限定某一子串成对出现。
| 表达式 | 说明 |
| \1\2 | 对序号为1和2的捕获组的反向引用 |
| \k<name> | 对命名为name的捕获组的反向引用 |
举例:
(a|b)\1 在匹配“abaa”时,匹配成功,匹配到的结果是“aa”。“(a|b)”在尝试匹配时,虽然既可以匹配“a”,也可以匹配“b”,但是在进行反向引用时,对应()中匹配的内容已经是固定的了。
查找:(t|T)(h|H) 替换:\1(abc)\2,效果是将th/TH单词替换为tabch/TabcH
查找:(a|b)\1,对文本aa或bb时匹配成功,因为\1进行了反向引用。
示例内容:Is is the cost of of gasoline going up up?
表达式:\b([a-z]+)\b \1
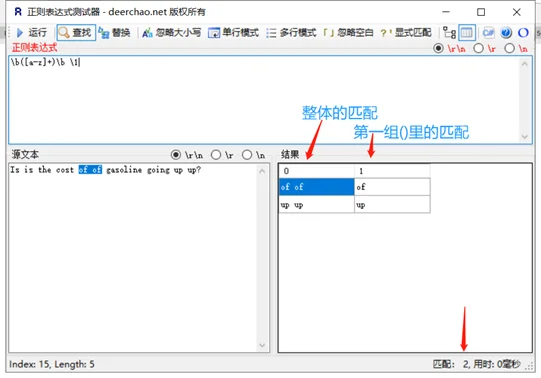
对匹配进行限制的示例
匹配自身,但不捕获:a(?:b|c)
- 可以找到 ab 和 ac ,但无法引用()里的内容。
后面匹配的限制条件:a(?=b)、a(?!b)
- exp1(?=exp2):查找 exp2 前面的 exp1。
- exp1(?!exp2):查找后面不是 exp2 的 exp1。
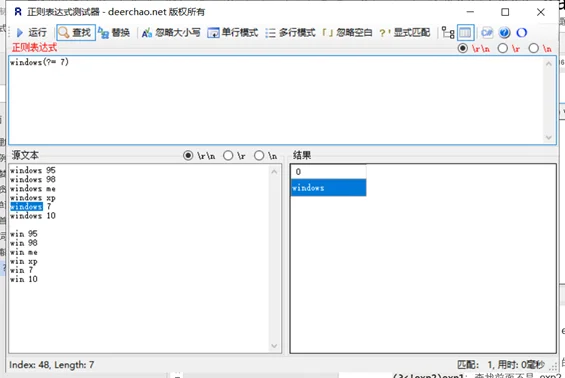
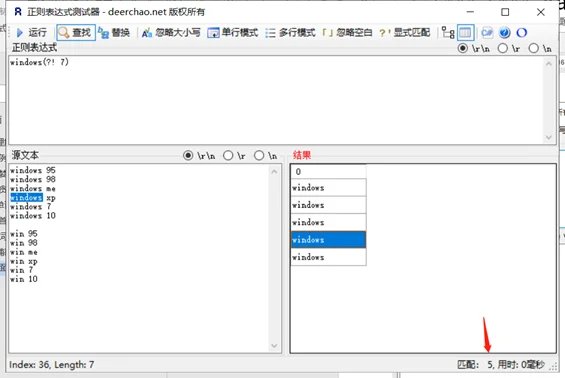
前面匹配的限制条件:(?<=a)b、(?<!a)b
- (?<=exp2)exp1:查找 exp2 后面的 exp1。
- (?<!exp2)exp1:查找前面不是 exp2 的 exp1。