举个例子:下面哪个结果是您所期望的?
源字符串:<div>aaa</div><div>bbb</div>
- 正则表达式1:<div>.*</div> 匹配结果:<div>aaa</div><div>bbb</div>
- 正则表达式2:<div>.*?</div> 匹配结果:<div>aaa</div>
标准量词修饰的子表达式,在可匹配可不匹配的情况下,总会先尝试进行匹配,称这种方式为匹配优先,或者贪婪模式。此前介绍的一些量词,“{m}”、“{m,n}”、“{m,}”、“?”、“*”和“+”都是匹配优先的。
一些NFA正则引擎支持忽略优先量词,也就是在标准量词后加一个“?”,此时,在可匹配可不匹配的情况下,总会先忽略匹配,只有在由忽略优先量词修饰的子表达式,必须进行匹配才能使整个表达式匹配成功时,才会进行匹配,称这种方式为忽略优先。忽略优先量词包括“{m}?”、“{m,n}?”、“{m,}?”、“??”、“*?”和“+?”。
或者叫做正则表达式匹配的贪婪模式与非贪婪模式。而 * 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
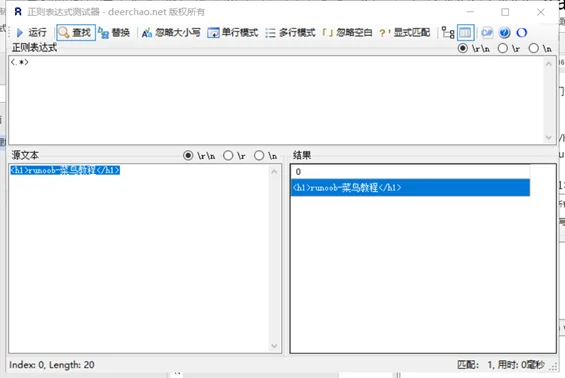
示例内容:<h1>runoob-菜鸟教程</h1>
1、贪婪模式/最大匹配模式:<.*>
查找结果只有1个,是<h1>runoob-菜鸟教程</h1>
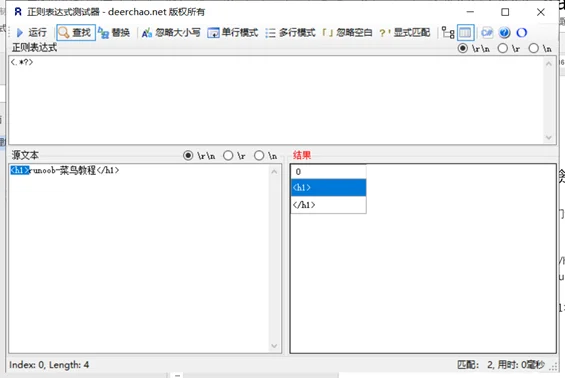
2、非贪婪模式/最小匹配模式:<.*?>
查找结果有2个,是:<h1> 与 </h1>
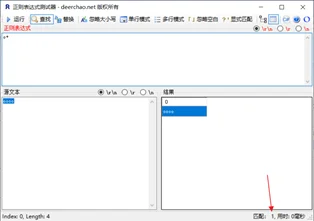
3、思考:oooo,使用o+、o+?来匹配的差异
o+ 匹配次数:1,结果:oooo
o+? 匹配次数:4,结果:o、o、o、o